







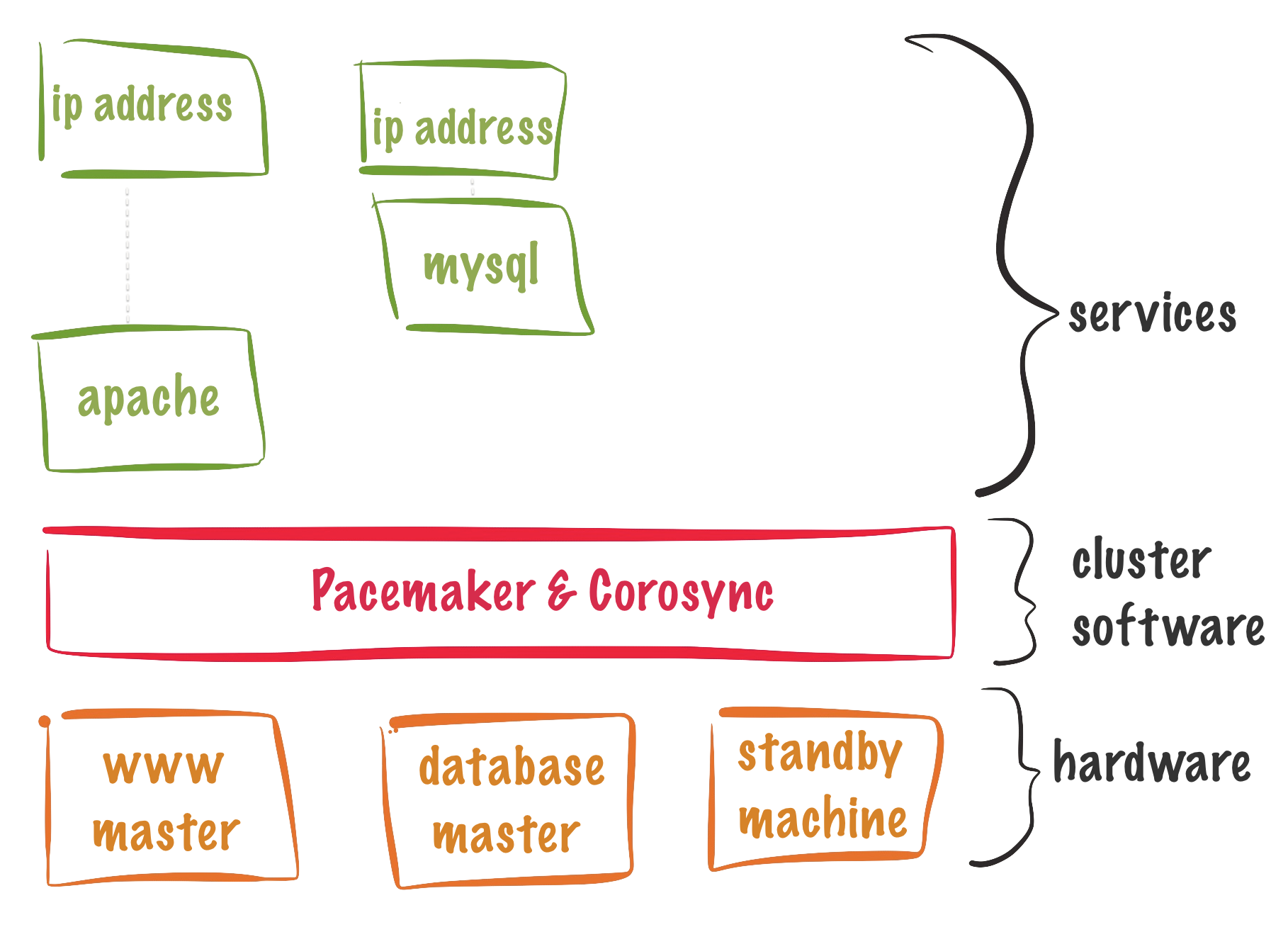
RHCA436-基于CentOS8pacemaker+corosync 集群监控与排错
日志配置
1.corosync日志
vim /etc/corosync/corosync.conf
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
to_stderr: yes #将错误日志转发至journal
debug: on
timestamp: on
}
使配置生效
pcs cluster sync
pcs cluster stop --all
pcs cluster start --all
tail /var/log/cluster/corosync.log
...
Feb 12 19:50:32 [22281] nodea.lab.example.com corosync debug [KNET ] pmtud: Starting PMTUD for host: 2 link: 0
Feb 12 19:50:32 [22281] nodea.lab.example.com corosync debug [KNET ] udp: detected kernel MTU: 1500
Feb 12 19:50:32 [22281] nodea.lab.example.com corosync debug [KNET ] pmtud: PMTUD completed for host: 2 link: 0 current link mtu: 1397
2.pacemaker日志
vim /etc/sysconfig/pacemaker
PCMK_logfile=/var/log/pacemaker/pacemaker.log
PCMK_debug=yes
scp /etc/sysconfig/pacemaker nodeb:/etc/sysconfig/pacemaker
scp /etc/sysconfig/pacemaker nodec:/etc/sysconfig/pacemaker
使配置生效
pcs cluster stop --all
pcs cluster start --all
查看日志
tail /var/log/pacemaker/pacemaker.log
实验:查看logs
1.准备运行环境
[student@workstation ~]$ lab start troubleshooting-logs
2.将nodea节点网络中断
[root@nodea ~]# ./firewall-script/firewall-block.sh
[root@nodea firewall-script]# cat firewall-block.sh
#!/bin/bash
firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP
firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop'
3.查看nodea节点的资源状态处于丢失
[root@nodeb ~]# grep crm_update_peer_state_iter /var/log/pacemaker/pacemaker.log
Feb 12 09:24:15 nodeb.lab.example.com pacemaker-controld [9179] (crm_update_peer_state_iter) notice: Node nodea.private.example.com state is now lost | nodeid=1 previous=member source=crm_reap_unseen_nodes
Feb 12 09:24:48 nodeb.lab.example.com pacemaker-fenced [9175] (crm_update_peer_state_iter) notice: Node nodea.private.example.com state is now member | nodeid=1 previous=unknown source=crm_update_peer_pro
4.查看fence记录
[root@nodeb ~]# grep te_fence_node /var/log/pacemaker/pacemaker.log
Feb 12 09:24:16 nodeb.lab.example.com pacemaker-controld [9179] (te_fence_node) notice: Requesting fencing (reboot) of node nodea.private.example.com | action=1 timeout=180000
5.查看nodea被fence后重启了
[root@nodeb ~]# grep tengine_stonith_notify /var/log/pacemaker/pacemaker.log
Feb 12 09:24:25 nodeb.lab.example.com pacemaker-controld [9179] (tengine_stonith_notify) notice: Peer nodea.private.example.com was terminated (reboot) by nodec.private.example.com on behalf of pacemaker-controld.9179: OK | initiator=nodeb.private.example.com ref=8518046f-e12e-44ce-9e40-ce4750af5de6
6.查看修改pacemaker配置中log配置的playbook
[student@workstation ~]$ cat labs/troubleshooting-logs/playbook.yml
---
- name: Ensure pacemaker configuration to log at DEBUG level
hosts: nodes
become: yes
gather_facts: no
tasks:
- name: Ensuring pacemaker configuration is configured
lineinfile:
path: /etc/sysconfig/pacemaker
regex: "^# PCMK_debug=no"
line: "PCMK_debug=yes"
state: present
- name: Ensuring pacemaker configuration is loaded
command:
cmd: "{{ item }}"
with_items:
- pcs cluster stop --all
- pcs cluster start --all
run_once: yes
...
7.清理环境
[student@workstation ~]$ lab finish troubleshooting-logs
实验:监控和发送邮件
- 创建资源告警邮件,集群发生一些时间后可以发送邮件
- 如果想要更详细的监控集群,可以用alert代理,发生事件后发送邮件
- 脚本模板路径/usr/share/pacemaker/alert/**.sh
- 可以根据模板进行修改
1.准备工作
[student@workstation ~]$ lab start troubleshooting-notification
2.在workstation节点安装邮件服务
[student@workstation ~]$ cd labs/troubleshooting-notification/
[student@workstation troubleshooting-notification]$ ls
ansible.cfg inventory playbook.yml prepare-nodes.yml prepare-workstation.yml
[student@workstation troubleshooting-notification]$ cat prepare-workstation.yml
---
- name: Ensure the postfix and mutt are installed
hosts: localhost
connection: local
become: yes
gather_facts: no
tasks:
- name: Ensure packages in workstation
yum:
state: present
name:
- postfix
- mutt
- name: Ensure Mail directory for student user
file:
path: /home/student/Mail
state: directory
owner: student
group: student
mode: '0700'
- name: Ensure right parameters for postfix
command: postconf -e 'inet_interfaces = all'
- name: Ensuring the required ports are open
firewalld:
service: smtp
permanent: yes
state: enabled
immediate: yes
- name: Ensuring the postfix service is started and enabled
service:
name: postfix
state: started
enabled: yes
...
[student@workstation troubleshooting-notification]$ ansible-playbook -e ansible_become_password=student prepare-workstation.yml
#创建资源告警邮件,集群发生一些时间后可以发送邮件
[root@nodea ~]# pcs resource create webmail MailTo email=student@workstation.lab.example.com subject='LUCTSER-NOTIFICATION' --group=firstweb
Assumed agent name 'ocf:heartbeat:MailTo' (deduced from 'MailTo')
[root@nodea ~]# pcs resource status
* Resource Group: firstweb:
* firstwebip (ocf::heartbeat:IPaddr2): Started nodea.private.example.com
* firstwebfs (ocf::heartbeat:Filesystem): Started nodea.private.example.com
* firstwebserver (ocf::heartbeat:apache): Started nodea.private.example.com
* webmail (ocf::heartbeat:MailTo): Started nodea.private.example.com
#如果想要更详细的监控集群,可以用alert代理,发生事件后发送邮件
3.准备alert脚本
[student@workstation troubleshooting-notification]$ ansible-playbook playbook.yml
- name: Ensure the agent script is installed
hosts: nodes
become: yes
gather_facts: no
tasks:
- name: Copying agent script file to the nodes
copy:
src: /usr/share/pacemaker/alerts/alert_smtp.sh.sample
dest: /var/lib/pacemaker/alert_smtp.sh
owner: hacluster
group: haclient
mode: 0755
remote_src: yes
...
4.配置alert
[root@nodea ~]# pcs alert create id=mailme path=/var/lib/pacemaker/alert_smtp.sh options email_sender=donotreplay@example.com
[root@nodea ~]# pcs alert recipient add mailme value=student@workstation.lan.example.com
[root@nodea ~]# pcs alert show
Alerts:
Alert: mailme (path=/var/lib/pacemaker/alert_smtp.sh)
Options: email_sender=donotreplay@example.com
Recipients:
Recipient: mailme-recipient (value=student@workstation.lan.example.com)
5.测试
pcs resource move firstweb
6.查看邮件
[student@workstation ~]$ mail
Heirloom Mail version 12.5 7/5/10. Type ? for help.
"/var/spool/mail/student": 3 messages
> 1 root Sat Feb 12 10:22 28/1201 "LUCTSER-NOTIFICATION Takeover in progress at S"
2 root Sat Feb 12 10:38 26/1181 "LUCTSER-NOTIFICATION Migrating resource away a"
3 root Sat Feb 12 10:38 26/1172 "LUCTSER-NOTIFICATION Takeover in progress at S"
&
7.删除alert
[root@nodea ~]# pcs alert remove mailme
8.清除环境
[student@workstation ~]$ lab finish troubleshooting-notification
实验:资源失败排错
1.准备工作
[student@workstation ~]$ lab start troubleshooting-resource
2.查看资源报错
# pcs status
firstweb:
* firstwebip (ocf::heartbeat:IPaddr2): Started nodec.private.example.com
* firstwebfs (ocf::heartbeat:Filesystem): Started nodec.private.example.com
* firstwebserver (ocf::heartbeat:apache): Stopped
3.查看webserver资源的失败次数
[root@nodea alerts]# pcs resource failcount show firstwebserver
Failcounts for resource 'firstwebserver'
nodea.private.example.com: INFINITY
nodeb.private.example.com: INFINITY
nodec.private.example.com: INFINITY
4.debug错误
[root@nodea alerts]# pcs resource debug-start firstwebserver
Operation start for firstwebserver (ocf:heartbeat:apache) returned: 'not installed' (5)
> stderr: ocf-exit-reason:Configuration file /etc/htttpd/conf/httpd.conf not found!
> stderr: ocf-exit-reason:environment is invalid, resource considered stopped
查看详细信息
[root@nodea alerts]# pcs resource debug-start firstwebserver --full
[root@nodea ~]# pcs resource config firstwebserver
Resource: firstwebserver (class=ocf provider=heartbeat type=apache)
Attributes: configfile=/etc/htttpd/conf/httpd.conf #写错了
Operations: monitor interval=10s timeout=20s (firstwebserver-monitor-interval-10s)
start interval=0s timeout=40s (firstwebserver-start-interval-0s)
stop interval=0s timeout=60s (firstwebserver-stop-interval-0s)
5.排错,修改参数
[root@nodea ~]# pcs resource update firstwebserver configfile=/etc/httpd/conf/httpd.conf
6.查看资源正常
[root@nodea ~]# pcs resource status
* Resource Group: firstweb:
* firstwebip (ocf::heartbeat:IPaddr2): Started nodec.private.example.com
* firstwebfs (ocf::heartbeat:Filesystem): Started nodec.private.example.com
* firstwebserver (ocf::heartbeat:apache): Started nodec.private.example.com
7.清除环境
[student@workstation ~]$ lab finish troubleshooting-resource
实验:网络防火墙排错
1.准备工作
[student@workstation ~]$ lab start troubleshooting-issue
2.查看集群状态
#节点nodec掉线
[root@nodea ~]# corosync-quorumtool
Quorum information
------------------
Date: Sat Feb 12 11:29:21 2022
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1.d
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 1 nodea.private.example.com (local)
2 1 nodeb.private.example.com
3.在nodec上查看
#集群已经分裂了,和另外两个节点失去联系,猜想可能是心跳故障
[root@nodec ~]# corosync-quorumtool
Quorum information
------------------
Date: Sat Feb 12 11:30:42 2022
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 3
Ring ID: 3.d
Quorate: No
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 1
Quorum: 2 Activity blocked
Flags:
Membership information
----------------------
Nodeid Votes Name
3 1 nodec.private.example.com (local)
4.测试网络
[root@nodec ~]# ping nodea
PING nodea.lab.example.com (172.25.250.10) 56(84) bytes of data.
64 bytes from nodea.lab.example.com (172.25.250.10): icmp_seq=1 ttl=64 time=1.60 ms
5.查看防火墙
5405是corosync集群内通信和心跳的端口
(pacemaker负责仲裁指定谁是活动节点、IP地址的转移、本地资源管理系统)、消息传递层负责心跳信息(heartbeat、corosync)
#firewalld防火墙规则
[root@nodec ~]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: eth0 eth1 eth2 eth3
sources:
services: cockpit dhcpv6-client high-availability http ssh
ports:
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
rule family="ipv4" port port="5405" protocol="udp" drop
#查看表和链上的规则
[root@nodec ~]# firewall-cmd --direct --get-all-rules
ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP
6.删除所有的规则
firewall-cmd --permanent --remove-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop'
或者执行
firewall-cmd --direct --remove-rules ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP
7.集群恢复正常
[root@nodec ~]# corosync-quorumtool
Quorum information
------------------
Date: Sat Feb 12 11:40:32 2022
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 3
Ring ID: 1.11
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 1 nodea.private.example.com
2 1 nodeb.private.example.com
3 1 nodec.private.example.com (local)


