







python-Django一
WSGI
WSGI协议: 如何调用传参,如何处理返回值;
- WSGI(Web Server Gateway Interface)主要规定了服务器端和应用程序间的接口。
- WEB Server主要负责HTTP协议请求和响应,但不一定支持WSGI接口访问。
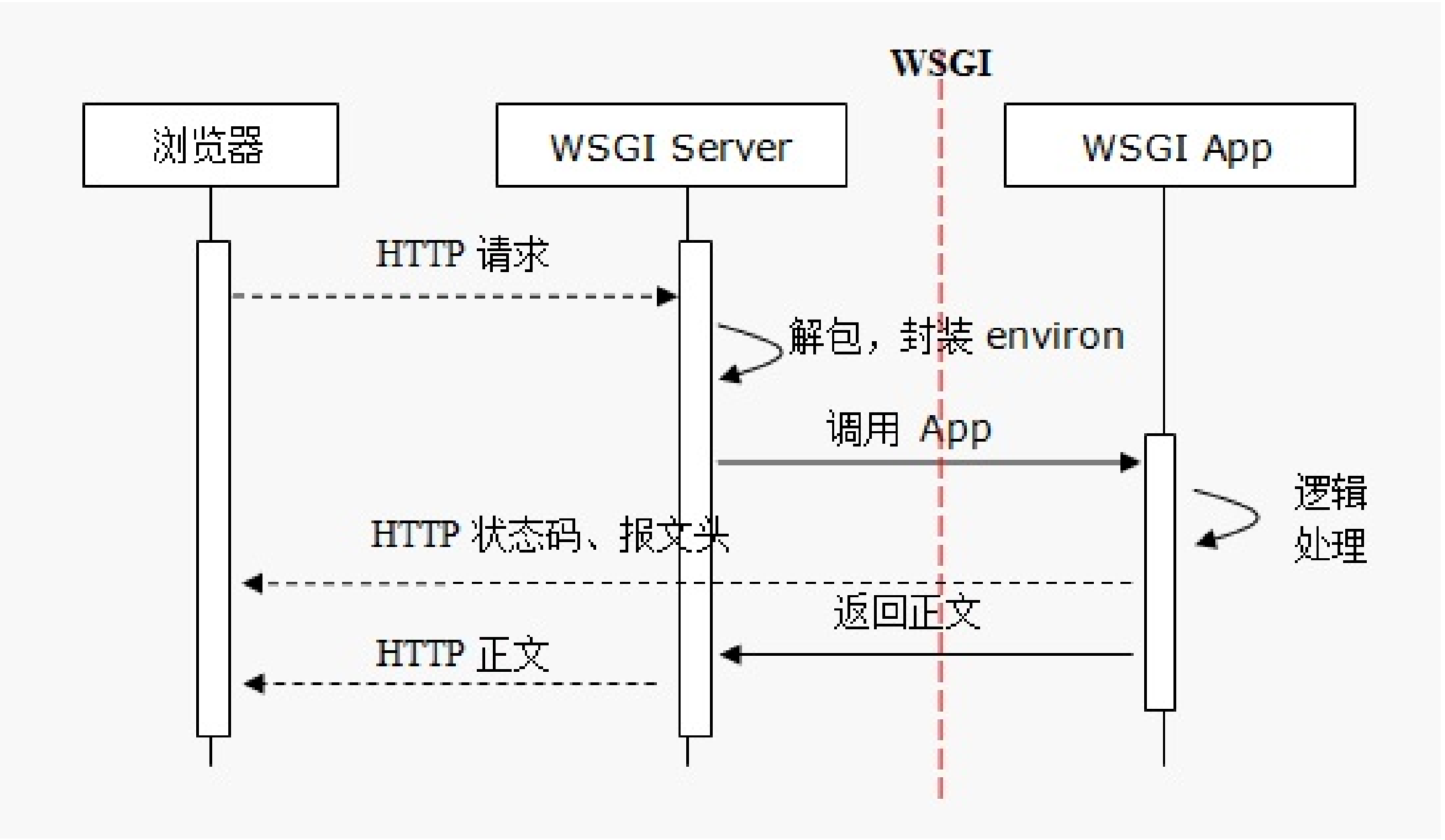
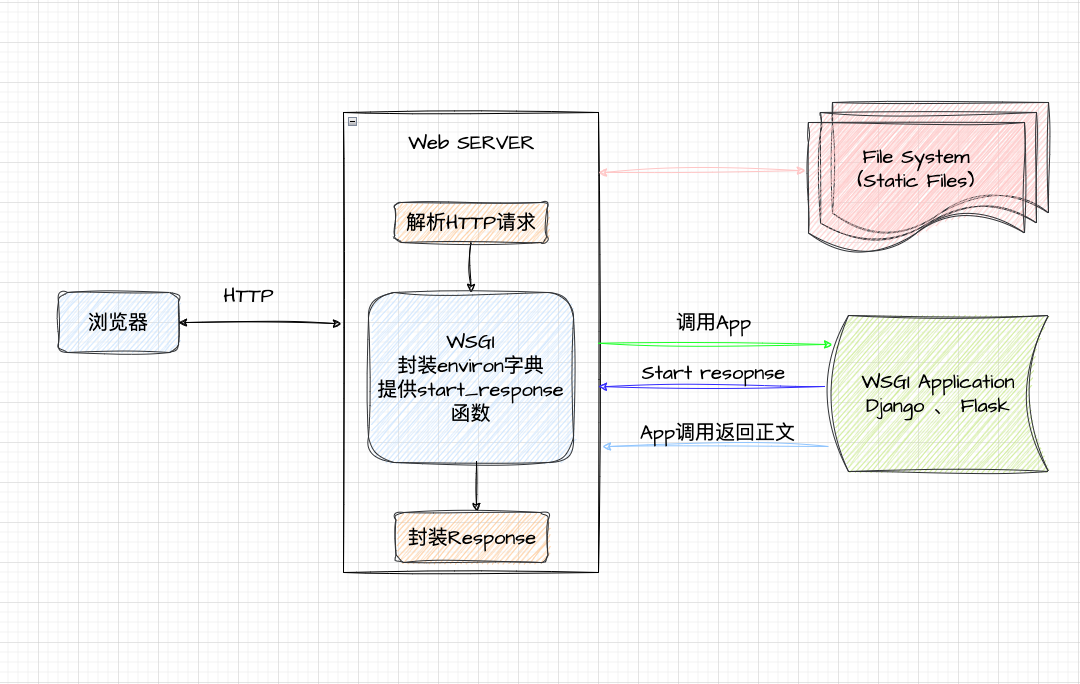
- environ是简单封装的请求报文的字典
- start_response解决响应报文头的函数
- app函数返回响应报文正文,简单理解就是HTML
WSGI服务器——wsgiref
wsgiref是Python提供的一个WSGI参考实现库,不适合生产环境使用。wsgiref.simple_server 模块实现一个简单的WSGI HTTP服务器。
# 启动一个WSGI服务器 wsgiref.simple_server.make_server(host, port, app, server_class=WSGIServer, handler_class=WSGIRequestHandler) # 一个两参数函数,小巧完整的WSGI的应用程序的实现 wsgiref.simple_server.demo_app(environ, start_response)
# 返回文本例子 from wsgiref.simple_server import make_server, demo_app ip = '127.0.0.1' port = 9999 server = make_server(ip, port, demo_app) # demo_app应用程序,可调用 server.serve_forever() # server.handle_request() 执行一次
WSGI APP应用程序端
- 应用程序应该是一个可调用对象
Python中应该是函数、类、实现了 __call__ 方法的类的实例
- 这个可调用对象应该接收两个参数
# 1 函数实现 def application(environ, start_response): pass # 2 类实现 class Application: def __init__(self, environ, start_response): pass # 3 类实现 class Application: def __call__(self, environ, start_response): pass
- 以上的可调用对象实现,都必须返回一个可迭代对象
from wsgiref.simple_server import make_server # 定义响应内容 res_str = b'www.testpage.com\n' # 函数实现方式 def application_func(environ, start_response): # 设置响应状态和头部信息 start_response("200 OK", [('Content-Type', 'text/plain; charset=utf-8')]) # 返回响应内容 return [res_str] # 类实现方式(使用 __iter__ 方法) class ApplicationIter: def __init__(self, environ, start_response): self.env = environ self.start_response = start_response def __iter__(self): # 设置响应状态和头部信息 self.start_response('200 OK', [('Content-Type', 'text/plain; charset=utf-8')]) # 返回响应内容 yield res_str # 类实现方式(使用 __call__ 方法) class ApplicationCall: def __call__(self, environ, start_response): # 设置响应状态和头部信息 start_response('200 OK', [('Content-Type', 'text/plain; charset=utf-8')]) # 返回响应内容 return [res_str]
environ
- environ是包含Http请求信息的dict字典对象
| 名称 | 含义 |
|---|---|
| REQUEST_METHOD | 请求方法,GET、POST等 |
| PATH_INFO | URL中的路径部分 |
| QUERY_STRING | 查询字符串 |
| SERVER_NAME | 服务器名 |
| SERVER_PORT | 服务器端口 |
| HTTP_HOST | 地址和端口 |
| SERVER_PROTOCOL | 协议 |
| HTTP_USER_AGENT | UserAgent信息 |
start_response
它是一个可调用对象。有3个参数,定义如下:start_response(status, response_headers, exc_info=None)
| 参数名称 | 说明 |
|---|---|
| status | 状态码和状态描述,例如200 OK |
| exc_info | 在错误处理的时候使用 |
| response_headers | 一个元素为二元组的列表,例如 [(‘Content-Type’, ‘text/plain;charset=utf-8’)] |
| start_response | 应该在返回可迭代对象之前调用,因为它是Response Header。返回的可迭代对象是Response Body。 |
服务器端
服务器程序需要调用符合上述定义的可调用对象APP,传入environ、start_response,APP处理后,返回响应头和可迭代对象的正文,由服务器封装返回浏览器端。
from wsgiref.simple_server import make_server def application(environ, start_response): # 设置 HTTP 状态码和响应头部信息 status = '200 OK' headers = [('Content-Type', 'text/html;charset=utf-8')] start_response(status, headers) # 构建 HTML 页面内容并转换为字节串 html = '<h1>Test Page</h1>'.encode("utf-8") # 返回包含 HTML 内容的可迭代对象 return [html] # 定义服务器的 IP 地址和端口号 ip = '127.0.0.1' port = 9999 # 创建一个简单的 HTTP 服务器,并指定请求处理函数为 application server = make_server(ip, port, application) # 启动服务器,让它一直运行 server.serve_forever() # 或者使用以下代码,处理一次请求后就停止 # server.handle_request()
总结
WSGI 服务器作用
- 监听HTTP服务端口(TCPServer,默认端口80)接收浏览器端的HTTP请求,这是WWW Server的 作用
- 解析请求报文封装成
environ环境数据 - 负责调用应用程序app,将
environ数据和start_response方法两个实参传入给Application - 利用app的返回值和
start_response返回的值,构造HTTP响应报文 - 将响应报文返回浏览器端
2、3、4要实现WSGI协议,该协议约定了和应用程序之间接口(参看PEP333,https://www.python.org/dev/peps/pep-0333/)
WSGI APP应用程序
遵从WSGI协议 本身是一个可调用对象 调用start_response,返回响应头部 返回包含正文的可迭代对象
Django、Flask都是符合WSGI协议且可以快速开发的框架,但本质上是编写Application,说白了,就是 编写一个函数,这个函数签名为app(environ, start_response) ,这不过在app函数内部调用非常复杂而 已。比如要解决访问数据库、静态HTML页面读取、动态网页生成等。
# pip install django # django-admin startproject salary . # 这里是创建项目管理目录 # cd salary # tree . ├── __init__.py ├── asgi.py ├── settings.py ├── urls.py └── wsgi.py
- 重要文件说明
manage.py
本项目管理的命令行工具。可以用于应用创建、数据库迁移等操作。salary/settings.py- 本项目的全局核心配置文件,包含以下内容:
- 应用和数据库配置
- 模板和静态文件配置
- 中间件和日志配置
- 第三方插件配置等
blog/urls.py
URL路径映射配置文件,用于定义项目的URL路由。初始状态下,可能只配置了/admin的路由。blog/wsgi.py
定义WSGI接口信息,用于部署项目。一般情况下不需要修改。
- Django给我们提供了脚手架,提供了开发时用的临时的server
# setting.py 配置文件 DATABASES = { "default": { "ENGINE": "django.db.backends.mysql", "NAME": "test", "USER": "test", "PASSWORD": "xx", "HOST": "localhost", "PORT": "3306", } }
# brew install mysql-client pkg-config mysql # pip install mysqlclient
CentOS7环境安装相关的依赖的模块
# yum -y install mysql80-community-release-el7-11.noarch.rpm # yum clean all # yum -y install mysql-devel python3-devel gcc # pip install mysqlclient
# employee tree . . employee/ │ ├── admin.py # 应用后台管理声明文件 ├── models.py # 模型层 Model 类定义 ├── views.py # 定义 URL 响应函数或类 ├── migrations/ # 数据迁移文件生成目录 └── apps.py # 应用的信息定义文件
# settings.py , INSTALL_APPS 迁移的时候用到 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'employee', # 对应初始化的app应用名称 ]
# setting.py, 时区和本地化语言 LANGUAGE_CODE = 'zh-Hans'#'en-us' TIME_ZONE = 'Asia/Shanghai' #'UTC'
- 第一手的资料一定是官方文档,可以看到相关联的知识
djagno官方文档
djgano官方文档日志配置示例
loggin-ref
LOGGING = { "version": 1, "disable_existing_loggers": False, "handlers": { "console": { "class": "logging.StreamHandler", }, }, "root": { "handlers": ["console"], "level": "WARNING", }, "loggers": { "django.db.backends": { "handlers": ["console"], "level": 'DEBUG', "propagate": False, }, }, }
- 启动初始化项目测试环境报错
django.db.utils.NotSupportedError: MySQL 5.7 or later is required,是由于django4.1.3以上校验django与数据库版本导致的
vim ../../venv/lib/python3.9/site-packages/django/db/backends/base/base.py#self.check_database_version_supported() 关闭校验;
或者升级数据库的版本由5.5 升级到11.3.2-MariaDB
# mysql --> 登录节点后 # SET GLOBAL innodb_fast_shutdown=0; # SHOW GLOBAL VARIABLES LIKE '%innodb_fast_shutdown%'; # systemctl stop mariadb # yum remove mariadb-server # yum install MariaDB-server # systemctl status mariadb # systemctl start mariadb
再来执行本地的
# python manage.py runserver
- 注意这是测试用的server,而在生产环境中,用的是wsgi
但可以看到收到的提示You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.Run 'python manage.py migrate' to apply them.
那么可以开始把进程停掉后,开始迁移数据;
- 迁移:
- 制作迁移文件,对Django内部使用的类迁移,迁移文件已经有了;
- migrate迁移,真正建表
- 但是要注意以后自己写的model类,需制作迁移文件,和migrate迁移;
# python manage.py makemigrations (0.010) SELECT VERSION(), @@sql_mode, @@default_storage_engine, @@sql_auto_is_null, @@lower_case_table_names, CONVERT_TZ('2001-01-01 01:00:00', 'UTC', 'UTC') IS NOT NULL ; args=None; alias=default (0.010) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None; alias=default (0.010) SELECT table_name, table_type, table_comment FROM information_schema.tables WHERE table_schema = DATABASE() ; args=None; alias=default No changes detected # 发现没有变化
# python manage.py migrate # 开始迁移
再次运行python manage.py runserver 发现没有You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.Run 'python manage.py migrate' to apply them. 相关的提示了.
ORM
ORM,对象关系映射,对象和关系之间的映射,这样就可以使用面向对象的方式来操作数据库中的表.
- 关系模型和python对象之前的映射;
table => class, 表映射为类row => object, 行映射为实例cloumn => property, 字段映射为属性
举例, 有表student, 字段为id int, name vachar, age int 映射到Python为
class student: id = ? 某类型字段 name = ? 某类型字段 age = ? 某类型字段 最终得到实例 class Student: def __init__(self): self.id = ? self.name = ? self.age = ?
Django ORM
对模型对的CRUD,被Django ORM转换成相应的SQL语句以操作不同的数据源;
Model模型
| 字段类 | 说明 |
|---|---|
| AutoField | 自增的整数字段。如果不指定,Django 会为模型类自动增加主键字段。 |
| BooleanField | 布尔值字段,True 和 False。对应表单控件 CheckboxInput。 |
| NullBooleanField | 布尔值字段,允许 NULL 值。 |
| CharField | 字符串,max_length 设定字符长度。对应表单控件 TextInput。 |
| TextField | 大文本字段,一般超过4000个字符使用。对应表单控件 Textarea。 |
| IntegerField | 整数字段。 |
| BigIntegerField | 更大整数字段,8字节。 |
| DecimalField | 十进制浮点数字段。max_digits 表示总位数,decimal_places 表示小数点后的位数。 |
| DateField | 日期字段。auto_now=False 每次修改对象自动设置为当前时间,auto_now_add=False 对象第一次创建时自动设置为当前时间。 |
| TimeField | 时间字段。auto_now, auto_now_add 与 default 互斥。 |
| DateTimeField | 日期时间字段。auto_now, auto_now_add 与 default 互斥。 |
| FileField | 上传文件的字段。 |
| ImageField | 继承了 FileField 的所有属性和方法,但是对上传的文件进行校验,确保是一个有效的图片。 |
| EmailField | Email 地址字段,能做 Email 检验,默认 max_length=254。 |
| GenericIPAddressField | 支持 IPV4、IPv6 检验,缺省对应文本框输入。 |
| URLField | URL 字段,能做 URL 检验,默认 max_length=200。 |
缺省主键
缺省情况下,Django的每一个Model都有一个名为AutoField字段,如下id = models.AutoField(primary_key=True)
如果显式定义了主键,这种缺省主键就不会被创建了.
字段选项
| 值 | 说明 |
|---|---|
| db_column | 表中字段的名称。如果未指定,则使用属性名。 |
| primary key | 是否为主键。 |
| unique | 是否是唯一键。 |
| default | 缺省值。这个缺省值不是数据库字段的缺省值,而是新对象产生的时候被填入的缺省值。 |
| null | 表的字段是否可为null,默认为False。 |
| blank | Django 表单验证中,是否可以不填写,默认为False。 |
| db_index | 字段是否有索引。 |
关系类型字段
| 类 | 说明 |
|---|---|
| ForeignKey | 外键,表示一对多。可用于关联其他模型。例如:ForeignKey('production.Manufacturer') 或者 ForeignKey('self')。 |
| ManyToManyField | 表示多对多关系。 |
| OneToOneField | 表示一对一关系。 |
Model类
字段说明
字段定义通常使用Model类的类属性来对应数据库字段,如果不迁移,可能会与数据库字段定义不一致。
字段属性包括:
- primary_key: 是否为主键,默认为False。
- unique: 是否为唯一键,默认为False。
- null: 是否可以为null,默认为False,即必填。
- verbose_name: 字段的可视化名称。
- choices: 提供枚举值,每个枚举值都是一个二元组(value, label),其中value是存储用的值,label用于展示。例如,使用p.gender获取字段值的value,使用p.get_gender_display()获取对应的label。
管理器
管理器非常重要,有了它才能操作数据库。
每一个非抽象的Model类必须有一个Manager实例。如果不指定,Django会默认指定一个Manager,就是属性objects。
参考 https://docs.djangpproject.com/en/3.2/topics/db/managers/
实践
- 确保项目对应的数据库可以连接成功后
# employee --> models.py from django.db import models # Create your models here. ''' CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL, `birth_date` date NOT NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, `gender` smallint(6) NOT NULL DEFAULT '1' COMMENT 'M=1, F=2', `hire_date` date NOT NULL, PRIMARY KEY (`emp_no`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; ''' class Gender(models.IntegerChoices): MALE = 1, '男' # 调用的时候 .get_gender_display() 会返回 '男' FEMALE = 2, '女' # 调用的时候 .get_gender_display() 会返回 '女' # 类、类属性 # 表、字段 # 每一行数据库的数据 对应类的实例 class employee(models.Model): # Model 基类做了很多不可见的工作 class Meta: db_table = 'employees' emp_no = models.IntegerField(primary_key=True,verbose_name='工号') # 主键,其中 IntergerField 是字段类型,字段类型为整数,verbose_name 是字段的别名只在django的后台管理系统中显示,不会影响数据库表结构,primary_key=True 是主键 birth_date = models.DateField(verbose_name='出生日期') # 出生日期 DateField 是字段类型,字段类型为日期 first_name = models.CharField(max_length=14,verbose_name='名字') # 名字 CharField 是字段类型,字段类型为字符串,max_length=14 是最大长度 last_name = models.CharField(max_length=16,verbose_name='姓氏') # 姓氏 CharField 是字段类型,字段类型为字符串,max_length=16 是最大长度 gender = models.SmallIntegerField(choices=Gender.choices ,verbose_name='性别') # 性别 SmallIntegerField 是字段类型,字段类型为整数,choices 是选项,verbose_name 是字段的别名只在django的后台管理系统中显示,不会影响数据库表结构 hire_date = models.DateField() @property # property 装饰器,将方法伪装成属性 def name(self): return "[{} {}]".format(self.last_name,self.first_name) def __repr__(self): return "<E {} {}>".format(self.emp_no,self.name) __str__ = __repr__ # 这个是打印给自己调试时看着方便 '''以上表的所有字段已经定义完'''
# 项目目录下,即项目根目录下 --> 新建t1.py import os import django os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'salary.settings') django.setup(set_prefix=False) # 从wsgi.py 里找 --> get_wsgi_application --> django.setup(set_prefix=False) '''以上属于固定写法,开始写自己的测试代码''' from employee.models import employee # print(employee.objects.all()) # 查询所有数据,<QuerySet []> 返回一个空的查询集,<employee: employee object (10020)> ,将每一行数据都封装成了一个实例对象 mgr = employee.objects # Manager 管增删改查的对象 # 你可以不提供,默认提供objects: 如果你不提供,django会默认提供一个objects的Manager对象, 如果你提供了,就不会提供默认的objects emps = mgr.all() print(type(emps)) # emps是QuerySet类型的查询集,但是惰性的 for e in emps: print(type(e), e, e.emp_no, e.name) # 每一行都是Employee属性的实例对象 # <class 'employee.models.employee'> <E 10018 [Peha Kazuhide]> 10018 [Peha Kazuhide] # <class 'employee.models.employee'> <E 10019 [Haddadi Lillian]> 10019 [Haddadi Lillian] # <class 'employee.models.employee'> <E 10020 [Warwick Mayuko]> 10020 [Warwick Mayuko] print(e.gender,e.get_gender_display()) # 1 男 # 2 女
Django查询
在Django中,查询是一项重要且复杂的任务,与数据库的增删改操作相比,查询涉及更多的细节和技巧。
查询集
如果查询的是一批数据,那么返回的是一个结果的集合,称为查询集(QuerySet)。
- 它是
django.db.models.query.QuerySet的实例。 - 可以被视为可迭代对象。
惰性求值
创建查询集不会立即对数据库进行访问,直到调用方法使用数据时,才会实际访问数据库。
在以下情况下会立即求值:
- 迭代
- 序列化
- 条件语句
- 切片
- 获取长度
- repr()
- 布尔运算
缓存
# 如果有反复遍历的情况 print(emps._result_cache) # 有缓存的查询集 list_emps = list(emps) # 从缓存中取出来 for e in list_emps: print(e)
切片
分页功能实现,使用限制查询集。
查询集对象可以直接使用索引下标的方式(不支持负索引),相当于SQL语句中的limit和offset子句。
注意:使用切片返回的新的结果集,依然是惰性求值,不会立即查询。但是使用了切片步长,会立即查
询print(emps[10:]) # 切片,返回一个新的查询集,不会影响原来的查询集
注:在使用print函数打印结果集的时候,看到SQL语句有自动添加的LIMIT 21,这是怕打印的太长了。
使用for循环迭代就没了。
- 结果集方法
| 名称 | 返回值类型 | 说明 |
|---|---|---|
| all() | QuerySet | 返回所有对象的查询集。 |
| filter() | QuerySet | 过滤,返回满足条件的数据。 |
| exclude() | QuerySet | 排除,排除满足条件的数据。 |
| order_by() | QuerySet | 排序,注意参数是字符串。 |
| values() | QuerySet | 返回集合内的元素是字典,字典内是字段和值的键值对。 |
print(mgr.filter(emp_no=10010)) #这是关键字参数,返回的是一个查询集
对应调试的sql
SELECT `employees`.`emp_no`, `employees`.`birth_date`, `employees`.`first_name`, `employees`.`last_name`, `employees`.`gender`, `employees`.`hire_date` FROM `employees` WHERE `employees`.`emp_no` = 10010 LIMIT 21; args=(10010,);
| 名称 | 说明 |
|---|---|
| get() | 严格返回满足条件的单个对象。如果未能返回对象则抛出DoesNotExist异常;如果能返回多条,抛出MultipleObjectsReturned异常。 |
| count() | 返回当前查询的总条数。 |
| first() | 返回第一个对象。 |
| last() | 返回最后一个对象。 |
| exist() | 判断查询集中是否有数据,如果有则返回True。 |
print(mgr.exclude(emp_no=10010)) print(mgr.exclude(emp_no=10010).filter(pk=10020)) # 两者是and的关系,这个属于链式编程 print(mgr.exclude(emp_no=10010).order_by('-emp_no')) # 降序排列 print(mgr.order_by('pk')) # 升序排列,pk这里统一都代表主键,如果-pk 那么就是降序排列 print(mgr.filter(pk=10010).order_by('-pk').values()) # values() 返回的是一个字典的列表,[{'emp_no': 10010, 'birth_date': datetime.date(1963, 6, 1), 'first_name': 'Duangkaew', 'last_name': 'Piveteau', 'gender': 2, 'hire_date': datetime.date(1989, 8, 24)}] print(mgr.exclude(pk=10010).last()) # 返回最后一个, <employee: employee object (10020)>,这里的last()是一个方法,如果不存,返回None print(mgr.exclude(pk=10010).get()) # 这里会报 MultipleObjectsReturned: get() returned more than one employee -- it returned 9! 错误,因为get()返回的是一个对象,如果有多个对象,就会报错 ,因此使用get要注意严格只要一个对象 print(mgr.get(pk=10010)) # <E 10010 [Piveteau Duangkaew]> print(mgr.exclude(pk=10010).exists()) # 返回单值True,SELECT 1 AS `a` FROM `employees` WHERE NOT (`employees`.`emp_no` = 10010) LIMIT 1; args=(1, 10010); alias=default
字段查询(Field Lookup)表达式
字段查询表达式可以作为filter()、exclude()、get()等方法的参数,用于实现WHERE子句的功能。
语法
属性名称_比较运算符=值
注意:属性名和运算符之间使用双下划线。
| 名称 | 举例 | 说明 |
|---|---|---|
| exact | filter(isdeleted=False) | 严格等于,可省略不写 |
| startswith | filter(title__startswith=’天’) | 以什么开头,大小写敏感 |
| endswith | filter(title__endswith=’天’) | 以什么结尾,大小写敏感 |
| contains | exclude(title__contains=’天’) | 是否包含,大小写敏感 |
| isnull | filter(title__isnull=False) | 是否为null |
| isnotnull | filter(title__isnull=True) | 是否不为null |
| iexact | filter(title__iexact=’天’) | 忽略大小写的严格等于 |
| icontains | filter(title__icontains=’天’) | 忽略大小写的包含 |
| istartswith | filter(title__istartswith=’天’) | 忽略大小写的以什么开头 |
| iendswith | filter(title__iendswith=’天’) | 忽略大小写的以什么结尾 |
| in | filter(pk__in=[1,2,3,100]) | 是否在指定范围数据中 |
| gt | filter(id__gt=3) | 大于 |
| gte | filter(pub_date__gte=date(2000,1,1)) | 大于等于 |
| lt | filter(id__lt=3) | 小于 |
| lte | filter(pk__lte=6) | 小于等于 |
| year | filter(pub_date__year=2000) | 提取指定年份的数据 |
| month | filter(pub_date__month=1) | 提取指定月份的数据 |
| day | filter(pub_date__day=1) | 提取指定日期的数据 |
| week_day | filter(pub_date__week_day=1) | 提取指定星期几的数据 |
| hour | filter(pub_date__hour=12) | 提取指定小时的数据 |
| minute | filter(pub_date__minute=30) | 提取指定分钟的数据 |
| second | filter(pub_date__second=45) | 提取指定秒数的数据 |
print(mgr.filter(emp_no__gt=10010).filter(pk__lt=10015)) # emp_no__gt=10010 代表emp_no大于10010的数据, pk__lt=10015 代表pk小于10015的数据 filter 是and的关系 print(mgr.filter(pk__gt=10010),pk__lt=10015) # emp_no__gt=10010 代表emp_no大于10010的数据, pk__lt=10015 代表pk小于10015的数据 filter 是and的关系,与上面等价 print(mgr.filter(last_name__contains='P')) # # (0.060) SELECT `employees`.`emp_no`, `employees`.`birth_date`, `employees`.`first_name`, `employees`.`last_name`, `employees`.`gender`, `employees`.`hire_date` FROM `employees` WHERE `employees`.`last_name` LIKE BINARY '%P%' LIMIT 21; args=('%P%',); alias=default # <QuerySet [<E 10006 [Preusig Anneke]>, <E 10009 [Peac Sumant]>, <E 10010 [Piveteau Duangkaew]>, <E 10018 [Peha Kazuhide]>]> # __contains 是%P属于模糊搜索,属于效率较低的搜索,不建议使用 print(mgr.filter(last_name__startswith='P')) # P% 代表以P开头的数据,模糊匹配不建议使用 print(mgr.filter(last_name__endswith='P')) # %P 代表以P结尾的数据,模糊匹配不建议使用 # in 操作, 用的比较多 print(mgr.filter(pk__in=[10010,10015,10330])) # pk__in=[10010,10015,10020] 代表pk在10010,10015,10020中的数据 # and qs & qs from django.db.models import Q print(mgr.filter(emp_no__gt=10010).filter(pk__lt=10015)) # and print(mgr.filter(pk__gt=10010,pk__lt=10015)) #and print(mgr.filter(pk__gt=10010) & mgr.filter(pk__lt=10015)) #and print(mgr.filter(Q(pk__gt=10010) & Q(pk__lt=10015))) #and 以上四种情况出来的and使用的SQL语句是一样的 # OR | from django.db.models import Q print(mgr.filter(pk__in=[10010,10015,10020])) # 使用in方法的或 print(mgr.filter(pk__lt=10010) | mgr.filter(pk__gt=10015)) # 使用or方法的或 print(mgr.filter(Q(pk__lt=10010) | Q(pk__gt=10015))) # 使用Q方法的或 print(mgr.filter(~(Q(pk__lt=10010) | Q(pk__gt=10015)))) # 使用Q方法的非 # group aggregate from django.db.models import Count,Sum,Avg,Max,Min print(mgr.filter(pk__gt=10010).count()) print(mgr.filter(pk__gt=10010).aggregate(c=Count('emp_no'))) # (0.010) SELECT COUNT(`employees`.`emp_no`) AS `c` FROM `employees` WHERE `employees`.`emp_no` > 10010; args=(10010,); alias=default # {'c': 10} print(mgr.aggregate(Max('pk'),Min('pk'), Sum('pk'), Avg('pk'))) # SELECT MAX(`employees`.`emp_no`) AS `pk__max`, MIN(`employees`.`emp_no`) AS `pk__min`, SUM(`employees`.`emp_no`) AS `pk__sum`, AVG(`employees`.`emp_no`) AS `pk__avg` FROM `employees`; 结果为 {'pk__max': 10020, 'pk__min': 10001, 'pk__sum': 200210, 'pk__avg': 10010.5} print(mgr.filter(pk__gt=10010).values('pk').annotate(Count('pk'))) print(mgr.filter(pk__gt=10010).values('gender').annotate(Count('pk'))) # SELECT `employees`.`gender`, COUNT(`employees`.`emp_no`) AS `pk__count` FROM `employees` WHERE `employees`.`emp_no` > 10010 GROUP BY `employees`.`gender` ORDER BY NULL LIMIT 21; args=(10010,); <QuerySet [{'gender': 2, 'pk__count': 3}, {'gender': 1, 'pk__count': 7}]> for x in mgr.filter(pk__gt=10010).annotate(c=Count('pk')): print (type(x), x.c ,x.pk) # 这里看x.__dict__ 可以看到x的内容为一个字典 # <class 'employee.models.employee'> 1 10011 # <class 'employee.models.employee'> 1 10012 for x in mgr.filter(pk__gt=10010).annotate(c=Count('pk')).values(): print(x['c'],x['emp_no'])